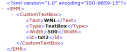
This Post I will describe you, how to convert string to date in Talend. I will use various string dates to demonstrate.
- Converting simple string with consistent format: “MM/dd/yyyy hh:mm”
12/21/2000 0:00
we will convert above date with “MM/dd/yyyy hh:mm” format. for that we will use below built in function from TalendDate routine.
TalendDate.parseDate(“MM/dd/yyyy hh:mm”,”12/21/2000 0:00″)
above function will return Date object if you print it will give you output as
Thu Dec 21 00:00:00 IST 2000
if you want this date in any other format then use below function.
TalendDate.formatDate(“dd-MMM-yyyy”, TalendDate.parseDate(“MM/dd/yyyy hh:mm”, “12/21/2000 0:00”))
TalendDate.formatDate(pattern, Dated) will return date in string type “21-Dec-2000” .
we can parse below non consistent formatted string using same method.
12/21/2000 0:00
5/11/2007 0:00
5/1/2009 0:00
- convert heterogeneous formatted string to date. Sample String dates are as follows.
2014/12/21
20140214
2014/12/13
2014/12/23
20141201
We will write some java code to replace “/” with non. so below code will replace “/” with empty string “” and then parse date function convert it using given format.
TalendDate.parseDate(“yyyyMMdd”, InputString.replaceAll(“/”, “”))
Convert dates with time stamp.
- Input String “2014-11-14T10:41:34-08:00”
- Format “yyyy-MM-dd’T’HH:mm:ssXXX”
TalendDate.parseDate(“yyyy-MM-dd’T’HH:mm:ssXXX”,”2014-11-14T10:41:34-08:00″)
- Input String: “2013-09-03T21:54:32.027+02:00”
- Format: “yyyy-MM-dd’T’HH:mm:ss.SSSX:00”
TalendDate.parseDate(“yyyy-MM-dd’T’HH:mm:ss.SSSX:00″,”2013-09-03T21:54:32.027+02:00”)
- Input String: “Tue May 08 00:00:00 CEST 2012”
- Format: “EEE MMM dd HH:mm:ss zzz yyyy”
TalendDate.parseDateLocale(“EEE MMM dd HH:mm:ss zzz yyyy”, “Tue May 08 00:00:00 CEST 2012”, “EN”)
- Input String: “30 Aug 2011 07:06:00”
- Format: “dd MMM yyyy HH:mm:ss”
TalendDate.parseDateLocale(“dd MMM yyyy HH:mm:ss”,”30 Aug 2011 07:06:00″,”EN”)
- Input String “24/02/2015 23:15:37.250000000”
- Format: “dd/MM/yyyy HH:mm:ss.SSSS”
System.out.println(TalendDate.parseDate(“dd/MM/yyyy HH:mm:ss.SSSS”, “24/02/2015 23:15:37.250000000”));
Parse DateTime-string with AM/PM marker
- Input String : “12/20/2012 10:02 PM”
- Format String: “MM/dd/yyyy HH:mm a”
System.out.println(TalendDate.parseDate(“MM/dd/yyyy HH:mm a”,”12/20/2012 10:02 PM”);
If you have any other format which is not listed here, then please send us we will include in list.
Keep visiting this page for newer formats.