I will demonstrate you, how to add custom header, footer to file. This is the often required functionality for file processing and validation.
Requirement: Create delimited file with below structure.
Header Part
File Name: Name of the actual File.
PID : process ID.
Header Columns.
Body Part
Text Data.
Footer Part
File Created Date: Date & Time.
Number of Records: record count.
This is our final job design.

Step 1: We`ll create Header part first.
Step 2: Add tFixedFlowInput component and configure as below.
- Add one column “value” with string type.
- Select “Use inline table” option and add three rows.
- Add each line of below code to the each line we created previously.
"File Name: CustomerDetails.csv"
"PID :"+pid
"Id,Name,City,State,Street"
- See the image for more details.

Step 3: Add tFileOutputDelimited and connect with tFixedFlowInput component using Main flow, then configured as follows.
- Add file path name “C:/home/CustomerDetails.csv”.(you can change this)
- Row separator=”n”
- Field Separator=”,”
Step 4: Add tRowGenerator and configured as explained in previous blog post.
Step 5: Copy Paste tFileOutputDelimited_1 component which we have created in Step 3, then connect tFileOutputDelimited_2 with tRowGenerator using main flow. Configure as follows.
- Select Option “Append”.
- Click on “Main” flow and go to the “Advance setting” tab and select option “Monitor this connection”.
- Unchecked “Use Input Connection as Label”. it will show you a “Label” and text box to write, write “Number Of Records:” in same text box.
Step 6: Create context variable named as “NumberOfRows”, then copy and paste tFixedFlowInput_1.
Step 7: Configure newly pasted tFixedFlowInput_2 component.
- Delete second last line from list.
- One second line add this code
"File Created Date: "+TalendDate.getDate("dd-MMM-yyyy HH:mm:ss"). - on third line add the context variable.
context.NumberOfRows.
Step 8: Copy paste tFileOutputDelimited_2 and connect with tFixedFlowInput_2 using main flow. no need to do any additional configuration.
Step 9: Add tFlowMeterCatcher component and add tJavaRow and connect each other using main flow, don`t click on “Synch” button on tJavaRow. Write below code in tJavaRow component.
context.NumberOfRows=input_row.label+input_row.count;
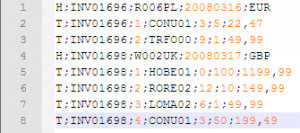
Step 10: Run the job it will create file with Header part, Data part and footer part. below is our final output.